
はじめに:AIの頭脳「LLM」を理解する
前回の記事では、テキストや画像を生成する「生成AI」の世界を探求しました。今回は、その中でも特にChatGPTなどの対話型AIの頭脳として機能する「大規模言語モデル(LLM: Large Language Model)」について、その構造と仕組みを徹底的に解剖していきます。
LLMは、なぜ人間のように自然な文章を生成し、複雑な質問に答えられるのでしょうか?その驚異的な能力の裏側には、膨大なデータと計算、そして革新的なアーキテクチャが存在します。
この記事を読めば、LLMが「大規模」である理由、その性能を決定づける重要な要素、そして中核技術である「トランスフォーマー」の仕組みまで、体系的に理解することができます。AI技術の最先端を理解するための鍵となる知識を、一緒に学んでいきましょう。
section 3-1:LLMとは何か? – 従来の言語モデルを超えるスケール
LLMとは何か? – 従来の言語モデルを超えるスケール
LLMの定義
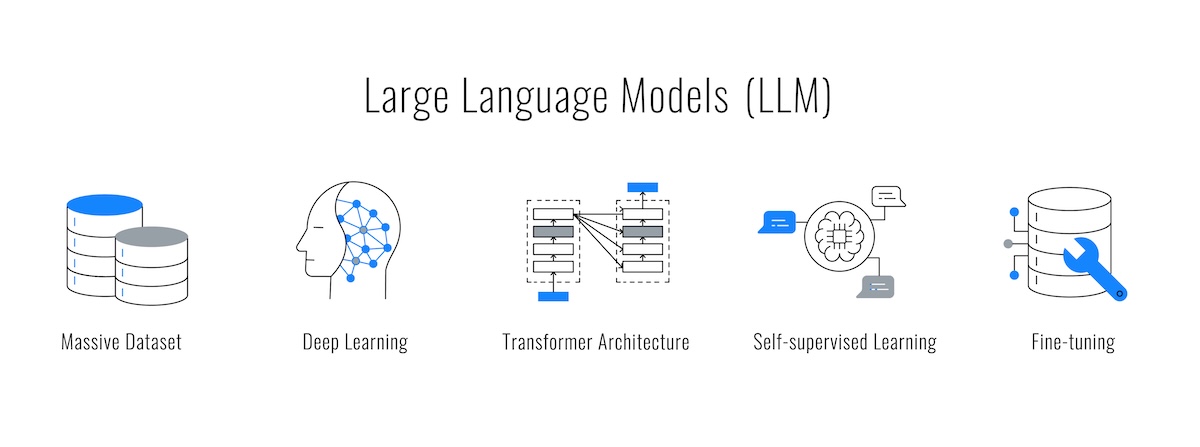
LLM(大規模言語モデル)とは、従来の言語モデルと比較して、「データセットサイズ」「計算量」「パラメータ数」が桁違いに大きい自然言語処理モデルのことです。これらの3つの要素が大規模であることにより、LLMはより賢く、精度の高い予測や文章生成が可能になります。
- 複雑なタスクへの柔軟な対応力
- より詳細な文脈理解能力
- 効率的な学習能力(並列処理の活用)
これらの特徴により、LLMは従来のモデルでは難しかった高度な言語タスクを実現しています。
LLMの性能を決める3つの重要要素
LLMの性能は、以下の3つの要素のスケールに大きく依存します。
データセットサイズ:知識の量
これはモデルが学習に使うデータの量、人間で言えば「読んだ本の量」に相当します。
インターネット上のニュース記事、書籍、ウェブサイトなど、膨大なテキストデータを学習することで、多様な言葉の使い方や文脈を学び、幅広い知識を獲得します。
データセットが小さいモデルは知識が限定的ですが、LLMは膨大なデータを学ぶことで複雑なタスクにも柔軟に対応できるのです。
計算量:知識を処理する力
これはモデルが学習や推論を行う際に必要な計算の量を指します。
簡単な計算とは異なり、LLMは大量のデータから単語同士の関係性や複雑な文脈を深く理解するために、膨大な計算を必要とします。
パラメータ数:学習能力の大きさ
パラメータとは、モデルが学習中に最適化する変数のことで、単語や文脈の関連性を数値で表します。
この数が多ければ多いほど、より複雑なパターンを学習できるポテンシャルを持ちます。
現在のLLMの中には、数百億から1兆を超えるパラメータを持つものも存在します。
補足:パラメータが多いとなぜ良いのか?
パラメータが多いモデルは、特定のタスクごとに事前学習を行う必要が少なくなり、少量の例や指示(プロンプト)だけで十分な性能を発揮できるという利点があります。
section 3-2:LLMの心臓部「トランスフォーマー」
現在のLLMの成功を支えているのが、2017年にGoogleの研究者によって発表された「トランスフォーマー(Transformer)」という画期的なモデルです。
トランスフォーマーの3つの強み
自己注意機構(Self-Attention)による高度な文脈理解
トランスフォーマーの中核をなすのが「自己注意機構」です。これは、文章中のある単語が、他のどの単語と強く関連しているかを「重み」として計算し、その重みに基づいて文脈を理解する仕組みです。これにより、文章全体の意味を広い視点で捉えることができます。
長距離依存の解消
従来のモデルでは難しかった、文章中で遠くに離れた単語同士の関係性も正確に捉えることができます。これにより、長い文章でも文脈を見失うことなく理解することが可能になりました。
並列処理による効率的な学習
トランスフォーマーは、文章の各部分を並行して処理できる「並列処理」に長けており、膨大なデータを効率的に学習することができます。これが、LLMの大規模化を可能にした大きな要因の一つです。
section 3-3:パラメータがもたらすLLMの驚異的な能力
パラメータ数が増えることで、LLMは具体的にどのような能力を獲得するのでしょうか。
多様な言語処理タスクへの対応力
質問応答、翻訳、要約、対話など、様々なタスクに対して、特別な微調整(ファインチューニング)なしでもある程度の高精度を発揮します。
人間らしさの向上: 微妙な文脈やニュアンスを捉え、人間が書いたかのような自然で創造的な文章を生成できます。
ゼロショット・ラーニング能力の向上
「ゼロショット・ラーニング」とは、特定のタスクについて事前に学習していなくても推論できる能力のことです。パラメータが多いLLMほどこの能力が高く、未知の質問や新しいパターンのタスクにも幅広く適応できます。
section 3-4:代表的なLLMモデル – GPTとGemini
現在、LLMの開発競争は激化していますが、その中でも代表的な2つのモデルシリーズを紹介します。
Open AIのChat GPTとGoogleのGeminiです。AnthoropicのClaudeもこれに続きますが、ここでは割愛します。
1. GPTシリーズ (OpenAI)
ChatGPTの概要
OpenAIが開発したLLMシリーズで、2018年の初代GPTから進化を続けています。
特に2020年に発表されたGPT-3は1750億ものパラメータを持ち、人間に近い自然な言語生成能力で世界に衝撃を与えました。
その後、2023年にはさらに進化したGPT-4、2025年にはGPT-5が登場しています。
Chat GPTの特徴と利用例
GPTシリーズは自然言語処理の分野で非常に高く評価されており、特にGPT-4は複雑なタスク処理や創造的な文章生成で優れた性能を示します。
多くのアプリケーションやサービスの基盤技術として広く利用されています。
2. Gemini (Google)
Geminiの概要
Google DeepMindが2023年に発表した最新のLLMです。
その前身には、テキスト理解に特化したBERT(2018年)やPaLM(2022年)といったモデルがあり、これらの技術を基盤として開発されました。
Geminiの特徴と利用例
Geminiの最大の特徴は、テキストだけでなく画像や音声なども同時に処理できる「マルチモーダル能力」と、高度な問題解決能力です。
計算効率も高く、AIエージェントによる自律的なタスク実行など、より先進的な応用が期待されています。
これを中心としたNotebookLMや、Google AI Studioといった関連サービスも非常に有用です。
section 3-5:LLMができること
LLMは、その高度な言語能力を活かして、具体的に以下のようなタスクを実行できます。
テキスト生成
マーケティングコピーや報告書など、自然で一貫性のある高精度な文章を自動生成します。物語や詩といったクリエイティブな文章作成も可能で、作家のインスピレーションを支援します。また、自然な対話を行うチャットボットにも応用されています。
質問応答
高い文脈理解力に基づき、高精度な応答を提供します。情報検索だけでなく、医療や法律といった専門分野での活用も期待されており、専門知識を含んだ回答が可能です。
翻訳と文章の要約
多言語データで訓練されているため、日常会話から専門文書まで高精度な翻訳が可能です。
また、ニュース記事や研究論文などの長文を簡潔に要約し、情報収集の時間と労力を大幅に削減します。
まとめ
今回は、現代AIの中核技術である「大規模言語モデル(LLM)」について、その基本構造から仕組みまでを深掘りしました。
- LLMは「データセットサイズ」「計算量」「パラメータ数」が巨大な言語モデルであり、これにより高い性能を実現している。
- その性能の根幹には、2017年に登場した「トランスフォーマー」アーキテクチャ、特に「自己注意機構」が存在する。
- パラメータ数が増えるほど、多様なタスクへの対応力や、未知の課題を解く「ゼロショット・ラーニング」能力が向上する。
- 代表的なモデルとしてOpenAIの「GPTシリーズ」やGoogleの「Gemini」があり、それぞれがAI技術の進化を牽引している。
LLMの仕組みを理解することで、AIがどのようにして「考えている」のか、その一端が見えてきたのではないでしょうか。
次回の記事では、この強力なLLMを実際に「賢く」するためのプロセスである「トレーニング」について、詳しく解説していきます。
